Pregel
Introduction
Pregel是Google在2010年发表的一篇文章。主要提出了一个富有表达性的和易于编程的图计算框架。Pregel是Euler七桥问题中那条河的名字。
Pregel的几大特点:
- 大规模(large-scale)
- 可扩展性(scalability)
- 容错性(fault-tolerant): 通过heartbeat、checkpointing和logging。
- 高效(efficient): MR也可以用来进行图计算,不过太过低效。
Contribution
Methods
Why Pregel?(Motivation)
进行分布式图计算的几种方法:
- 使用已有的分布式基础设施:对使用者较为复杂,而且每个新的算法都需要重新实现一遍一些较为基础的功能。总的来说,还是抽象层次较低,已有的分布式基础设施的API较为难用。给使用者提供一个抽象层次更高的东西即为框架,如何把这个抽象层做的通用(general)和高效(efficient)就是值得研究的问题了。(All problems in computer science can be solved by another level of indirection.)
- 使用类似于Mapreduce这样的已有的分布式计算框架:问题的pattern不同,可以做,但不高效。我们需要一个为图计算这种计算模式(pattern)设计一个特有的框架来提高效率。
- 使用已有的单机图计算库:不能scale。
- 已有的并行图计算系统(BGL、CGMgraph): 没有具体看,也不清楚这里并行是否可以进行分布式部署。文章中说:这些系统没有考虑容错性。
因此,pregel的作者们认为这些现有的东西都不能满足他们的需求(高效、容错性、可扩展性等),所以设计了Pregel。
计算模型
采用BSP(Bulk Synchronous Parallel)和消息传递(Message Passing),并以节点为中心(vertice-centric)。
关于BSP,我从wiki上找了张图: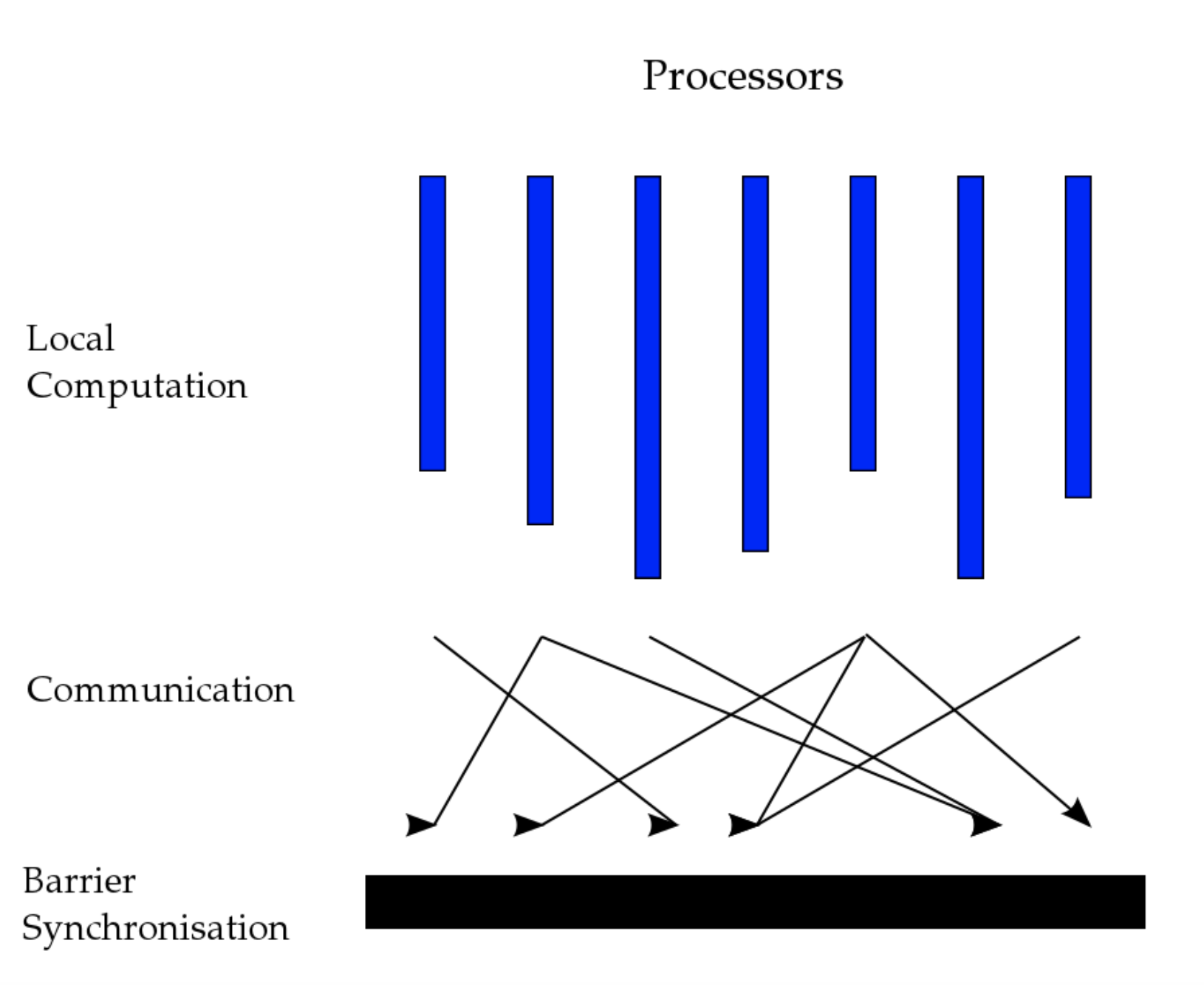
整个Pregel的计算模型也就是这张图,Pregel的计算是由一系列的superstep组成的,每个superstep就是上图的流程。这里的Local Computation就是每台机器对于自己所拥有的顶点展开计算。具体来说,对于每一个节点,先收集上一轮中传递过来的messages(已经存在本地了),然后做一些计算,得出需要发送的messages。在Communication阶段,将这些messages发送出去。
关于算法如何终止:只有活跃(active)的顶点才会进行Local Computation。当某一轮开始的时候,所有的顶点都不活跃了,那整个算法也就终止了。
关于活跃和不活跃的状态转换,paper中给了一张图:
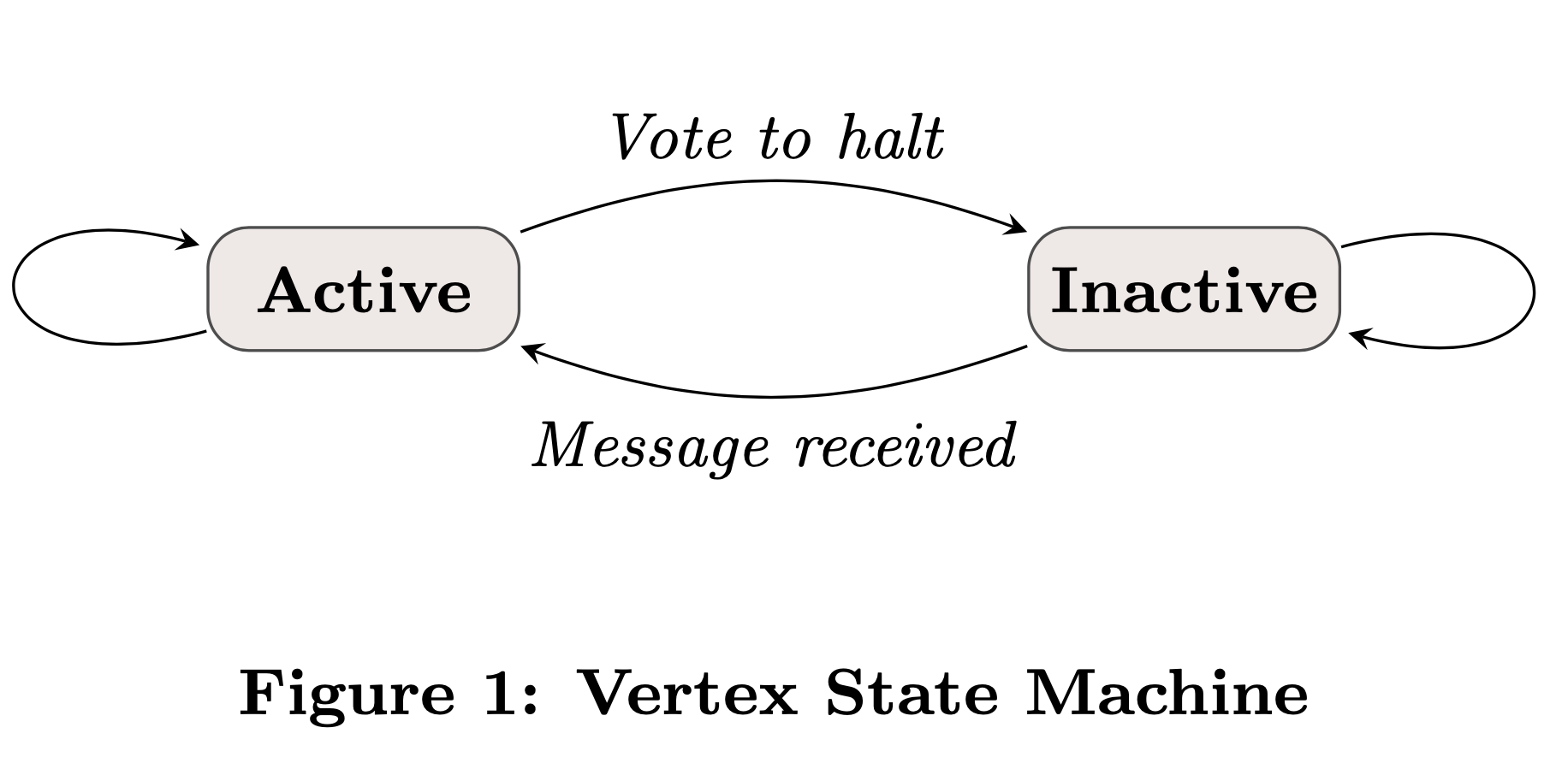
当然在第一轮的时候,所有顶点都是活跃状态的,不然程序直接结束了。
一些组件
Combiners: 聚合msg来减少通信量,一般是在msg发送端部署,比如在SSSP问题中,我们可以对发往同一个顶点的所有msg取MIN。基本上是个优化操作,没有也没什么关系,本质上是把下一轮Compute()里的操作提前了,在发送之前。
Aggregators: 一般用于全局通信,对所有节点提供的值进行规约,形成一个值,供下一轮使用。感觉halt的条件就可以看做是一个aggregator(AND(v1.isHalt(), v2.isHalt(), …))
Topology Mutations: 这个算个feature,可以动态改变拓扑结构(增删顶点和边)。可能会导致冲突,两个解决方法:
- 偏序(partial ordering): 删边-删点-增点-增边
- handlers: 可以user-defined,也可以default(随机选择)
但没看明白它的同步过程:猜测也是在message passing阶段,传递mutation,然后由每个顶点handle在Computate之前。顶点管理着自己和它的出边。
Implementation
顶点的分配就是hash: 即 hash(ID) % N, N是划分数。
整个集群的架构是Maste/Slave架构,整个流程如下:
- Worker向Master进行注册,并保持heartbeat。
- master进行数据集的划分,并给每个worker分配一些partition(可以多于一个),并且所有worker都知道整体的分配情况,这样worker就知道该往哪发msg。
- master给每个worker分配一部分输入文件,worker读取。对于不属于自己的数据,通过msg发送给相应的worker。所有的顶点现在都是活跃状态。
- master让所有worker开启一轮superstep,superstep的过程前面已经说过。实现上有一点优化:计算和通信是overlap的,可以提高效率。当所有worker完成后,告诉master一些信息,包括活跃顶点数,发送的msg数量等。如果有活跃顶点或者发送的msg,继续进行这一步。
- 计算结束,每个worker保存自己的那部分结果。
容错性:每几轮(freq可以指定)中worker保存顶点值、边值和收到的msg,master保存聚合的值,这叫checkpoint。通过heartbeat来探测状态。如果不保存发送的msg,所有partition都需要从某一个checkpoint重新计算。但是如果保存了发送的msg,只需要失败的partition重来即可, 但会使得保存的数据变多,这叫confined recovery. 随机算法需要保存随机数种子来使用confined recovery。
Worker实现:对于每个顶点:一份顶点值、一份边值、两份incoming queue(本轮和下一轮)。 对于out queue,应该是每个target worker有一个,queue是异步发送,到达一个threshold就发送。Combiner既在out queue上作用(节约带宽),也在incoming queue上作用(节约内存)。
Master实现:Master主要做一些管理工作,不多做赘述。
Aggregator: tree-based 而不是streaming,提高并行度。
Evaluation
Evaluation比较简单:大致是scalability比较好。
我的观察:Worker越多,cross edge也就越多(对于相同的图),因此scale不是线性的,也可能和一些固有的overhead有关。
Drawback
paper中没有提到,但我认为计算应该是完全基于incoming msg的,即不能随意读取非本节点的状态。
节点度比较大的时候,communication会比较大,可能需要较好的划分方法,让cross edge尽量少。
Related Works
Miscs
Web search for a planet: The Google Cluster Architecture.: 是03年的一篇文章,可以看到Google Web search的整个流程(比较老了,考古级文章)。从google的很多早期论文中都可以看出,google一直喜欢采用commodity PCs(注重performance per price),把reliability放在软件(replica)上,并通过shard等机制提高scalability。P.S. 第一次看到commodity PC这个词应该就是在google的文章里。 这篇文章里也总结了这几个principle:
- Software reliability
- Use replication for better requset throughput and availability
- Price/performance beats peak performance.
- Using commodity PCs reduces the cost of computation.
Google的当时的策略是选择中端产品,每隔至多三年全部替换(CPU性能在当时提升得很快)。
Hama: 正如Hadoop是MapReduce的开源实现一样,Hama是Pregel的开源实现
一些其他对于Pregel的分析文章:
- https://io-meter.com/2018/03/23/pregel-in-graphs/ : 逻辑清晰、配图精美。
Reference
[1]. Pregel Slides
[2]. BSP wikipedia